发布日期:2026-01-26 23:36 点击次数:91

英伟达A100和H20与国产CPU的性能差距因应用场景而异,前者在AI并行缠绵上上风显赫,后者在通用缠绵和系统协同中发达要害作用。这并非浅显的“谁更强”比拟,而是定位不同的硬件如安在不同任务中互补。
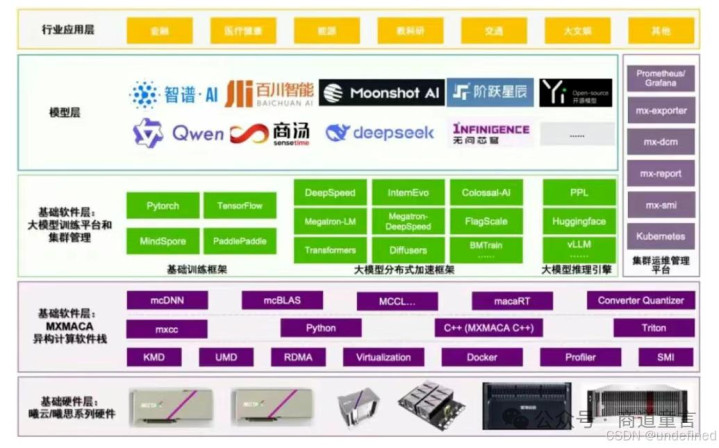
硬件定位与中枢参数英伟达A100和H20是专为AI遐想的加快GPU,而国产CPU如海光、华为鲲鹏、激越等是通用缠绵中枢,认真数据预处罚和任务转机。从中枢参数看: A100:FP16算力达312 TFLOPS,配备40GB或80GB显存,支捏高速NVLink互联,是中大界限AI考验的行业标杆。H20:动作中国特供版,FP16算力为148 TFLOPS,但领有96GB大显存,INT8性能凸起,主打高并发推理场景。国产CPU:举例海光CPU兼容x86辅导集,性能可对标英特尔至强中端居品;华为鲲鹏920支捏128核,与昇腾AI芯片协同后,单卡考验老本仅为入口有运筹帷幄的1/3。激越最新S5000C的算力较上一代擢升2.2倍,已完成百度、阿里等AI考验考证。更要害的是,在大模子使命流中,CPU需确保“内存容量≥GPU显存的2倍”以幸免数据瓶颈,中枢数在多卡场景下也需达到32以上。
场景下的性能表当今具体AI任务中,差距体现得更为彰着。关于AI考验,GPU的并行算力占主导:A100的FP16算力远超国产CPU内置加快单位,且多卡集群能撑捏千亿参数模子。但国产CPU通过异构协同优化,举例华为昇腾万卡集群在政务大模子考验中,算力应用率踏真是92%,考验周期裁汰25%。
在AI推理场景,差距因需求而异:
一项视频生成测试知道,A100环境平均耗时18.2秒,抢庄牛牛app而仅用CPU的环境耗时高达186.7秒,差距特出10倍。但在高并发推理中,H20凭借大显存成为优选,支捏32B模子250并发;国产有运筹帷幄如鲲鹏+昇腾组合,通过颐养内存池时期,推理延长评论40%,老本仅为H20的30%-70%,性能保捏率达92%。
{jz:field.toptypename/}
MLPerf 2025基准测试指出,基于昇腾芯片的LLM推理,隐晦量平均比A100低23.8%,延长高17.4%。这些数据标明,国产CPU在推理端通过协同遐想,正快速削弱性能差距。
生态与老本考量性能差距的背后,软件生态是更大挑战。英伟达的CUDA生态掩饰内行超200万设立者,而国产芯片与主流AI框架的适配度仅为CUDA的1/5,导致企业切换时濒临腾贵的调试老本。
但国产CPU凭借性价比和生态兼容找到了冲突口:
海光CPU因兼容x86,现存做事器可平滑升级,迁徙老本险些为零。华为、激越等分享软件栈,整机互认证超2000款,评论了设立门槛。价钱上,国产有运筹帷幄时时惟有对标英伟达GPU的30%-70%,始终使用老本更优。正如行业不雅察所指,国产芯片的瓶颈不仅是硬件参数,更是“隐性切换老本”——72%的机构在替换后3个月内仍受困于适度问题。
因此,国产CPU并非平直替代A100/H20,而是通过异构协同成为算力体系的性价比之选。跟着生态完善和制程高出,场景化替代已可行。
 备案号:
备案号: